Should you be using version control?
I love this graphic that sums it up perfectly:
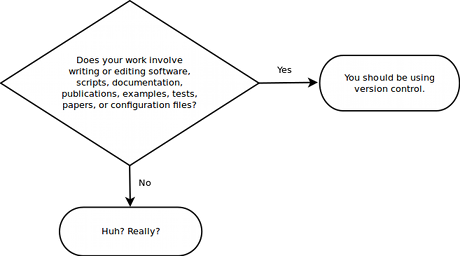
So let's talk about version control. It's something you have to use, right? When you work with code, especially on a team, it's a necessity. As a professional developer in most cases when you join a software company you won't even have a choice, you must use their choice of version control system in order to contribute to the team. However I would say that even for an amateur or hobbyist developer that version control is invaluable.
In this article I'll argue the benefits of version control. I'll help you understand the problems it solves and I'll show you how to use version control more effectively. I'll also expose the problems it can cause. I'll lay bare the unresolved problems with version control for the games industry.
I'll cover the particular software packages that I have used. My own experience goes way back to Microsoft Visual SourceSafe at my first programming job. It was almost enough to put one off version control! However since then I've battle-tested a number of other packages from both the traditional model and the newer distributed model. They all have their strengths and weaknesses and none are perfect.
Version control is important for your sanity on anything more than the most simple projects. However there's a world of pain and problems waiting for the uninitiated.
In addition there's an important choice you have to make. Which version control system should I use? There's no easy answer to that question, indeed there is no correct answer. You will have to accept something based on your needs. You must then learn to workaround the inadequacies of the system you have adopted (or choose a different system and accept its inadequacies instead).
I can help you understand why you should use version control and how you can make better use of it. Which software you use is far less important than the fact that you do use version control!
Contents
Table of Contents generated with DocToc
- Contents
- What is version control?
- I'm new to development, should I use version control?
- I'm working alone or on a small project, is it worth using version control?
- Should I convince my team mates to use it?
- What if I don't like using version control?
- I'm not a developer, should I use version control?
- Why use version control?
- Traditional or distributed?
- Version control and game development
- Version control and Unity
- Techniques for managing releases
- Using version control effectively
- Training
- Version control everything... except anything that can be installed or generated
- Code review
- Test before you commit, don't break the build!
- Be careful when you synchronize
- Commit messages
- It's your diary
- Make small frequent commits
- Push frequently
- Keep a clean copy of your repo
- Revert changes when you need to
- Testing
- Code freezes
- Branch or fork only when you need to
- Error recovery and bug investigation
- Blame
- Hooks
- Delete old code
- Merging
- Integrate with other tools
- Version Control Software
- Software to watch
- Alternatives to version control
- What we use at Real Serious Games
- Conclusion
- Resources
- Reviewers
- Special Thanks
What is version control?
Do I need to explain what version control is? Maybe not. Many others have already written extensively on this.
Here's a great visual guide that will help you understand exactly what version control is. Here's the visual guide to distributed version control.
Here's another good introduction that explains version control concepts.
Put briefly... version control allows you to manage changes over time. It is most commonly used to track revisions to source code. For game development we also track projects (eg Unity projects) and revisions to assets. It is like an undo system on steroids. Made a mistake? No problem, roll back to a previous revision or backout the offending change.
Changes are contributed to a version control repository by a team of developers. At any point you can get the current state of the entire repository, that's the sum of all changes. That's what you use to build the current version of your game.
I'm new to development, should I use version control?
Maybe. Consider that you'll need to learn it eventually.
However be careful that you don't get overwhelmed with the learning process. Before learning version control you should focus on being comfortable with writing code and making games.
If you are working on a team however... then they might mandate the use of version control. Or you might all decide it's worth learning version control together because it is simply the best way to coordinate a development team.
I'm working alone or on a small project, is it worth using version control?
Yes, definitely.
I use it even on small experimental or hobby projects. If I spend more than, say, an hour on any project. I version control it. It only takes a few minutes to set up a repository on your existing code. If the project becomes important or I want to share with the team, then I clone it and put it on the server. This takes another few minutes.
Of course the bigger the project and the team the more you will get out of version control. Small projects are great for learning new technologies like version control. Small projects are easier to manage and there is less pressure. Any use of new tech will inevitably lead to mistakes and you must plan for that and be ready to pay the cost. When the project is small we can afford to make mistakes because in this situation they are easier to rectify.
Modern version control is easy to start using. There's no excuse not to use it.
Should I convince my team mates to use it?
Yes.
Well, maybe. If your team is against using version control it might not be worth the battle, in that case save your energy for better things. It might even be easier to change your team than to convince them to use version control.
If your team mates are reluctant it could be simply that they just need to experience the pain of collaborative development without version control before they are willing to give it a go.
Education is one answer. If your team mates understand the need for version control they will want to use it. Internalize the arguments presented in this article and get to work swaying them to your point of view!
What if I don't like using version control?
That's an easy one. Just don't use it.
Although maybe you just don't like the first version control system you tried? Well, try a different software package and see if that is more to your liking. You have the benefit of choice.
Maybe you tried a traditional version control system, but you'd be better off with a distributed system? Or vice-versa.
Maybe you just aren't ready to use version control. That's ok. Trying using Dropbox or a USB stick to share your code with team mates. You'll soon understand why version control is useful.
I'm not a developer, should I use version control?
Yes. Well, maybe.
You can version all sorts of things with version control. It's most effective with text files, that's because version control systems are usually built for working with source code. You can also version binary files such as art assets, spreadsheets and documents, although this works better in some systems than others. This means you can version control almost any file you can imagine.
If you need to track and maintain versions of files, version control is for you and you don't need to be a developer to take advantage of it.
Writers can definitely use version control to track revisions of their books. Whole business models are being based on this, for example GitBook.
Data analysts can also make use of version control. Take a look at the DAT package for tabular data.
Why use version control?
Everyone has something to say on this topic. Here's my list of what version control can do for you...
Enables a safe workflow
Commit code in small and easily testable increments. If any commit causes a problem... it can easily be backed out.
Enables experimentation without fear
Experiment or refactor not working for out? Simply revert your work in progress back to a clean copy.
Messed up your local repository badly? Just delete it and clone a fresh copy from your master repository.
Rollback to a previous version
Version control allows rollback. That is the recovery of old versions of your code. That's why I call it an undo system on steroids.
Does the current version have a nasty bug? Recover a previously working version of the code.
Did you delete some code that you now need? Recover a copy of the deleted code.
Performance gone to hell? Find a previous version with good performance and that will help you understand what caused the problem.
Need to reconstruct a previous working version? Say you want to change and rebuild the PAX demo that you made 2 months ago. Step back in time using version control, make the changes you need and rebuild the demo.
Isolate a problematic revision
Using version control you can search through previous revision to find the point where an issue was introduced. This is helpful as finding the source of the problem is often 90% of the work.
Manage multiple versions
Use branches, forks or tagging to maintain multiple versions of a product. This is useful when you need to have multiple streams of development progressing in parallel and not interfering with each other. For example many developers maintain at least a well tested production version and a work in progress development version of their code.
Coordinate teamwork
Version control prevents absolute chaos when working in a development team. It enables collaborative work. Manually sharing and merging code is time-consuming and error-prone. If you are sharing a collaborative project via Dropbox or a similar alternative then you are flirting with disaster.
Understand a project's history
Version control allows you to understand the history of a project and what has happened. You can see who created a file and who last edited it. In fact you can see the complete history of edits, what has happened to each file since the beginning of time (as far as the repository is concerned, at least).
Version control allows the history of a code-base to be audited.
Backup
All PCs inevitably die. When your PC dies will it take your amazing project with it?
Using version control means that at minimum you should have a master version of your project on the server. If your PC dies then you'll only lose your most recent work that hasn't yet been integrated to the server.
What if your server dies? Well you either need an automated backup of your server. Or you should consider using a distributed version control system (DVCS) where cloning the repository to a backup drive is trivial.
Enables continuous-integration and continuous-delivery
Whilst not a focus of this article, continuous-integration (CI) and continuous-delivery (CD) are very important techniques for scaling up a development team and automating builds, testing and deployment. Version control is a crucial enabler for these advanced techniques.
Traditional or distributed?
In this section I introduce the two different models of version control. This is an introduction to the concepts followed by a concise list of the pros/cons of each as I see it.
For more on this, Atlassian have a nice comparison of the models with lots of visuals and diagrams.
Traditional version control
Traditional version control systems rely upon a centralized server. In this model multiple clients talk to a shared server to commit changes and work with the revision history. Clients have what is known as a working copy, that's a copy of all the files with the accumulation of changes to date. Changes to the working copy are committed directly to the shared server. Whenever a client commits a change, that change is immediately available to all other clients.
Pros
- The client-server model is easy for people to understand as client-server programs, such as FTP, have been around for a long time.
- It works well in a traditional office environment. People working together on a private LAN where all have convenient access to a server.
- The software is mature and robust.
- There's only a single server, so it's easy to remember when your code is, although it can still get out of hand if you use a lot of branches.
- In most software it is possible to lock files for editing. This helps to prevents multiple people from editing binary files.
- Repositories can be partially synchronized. This is useful when you need to get a part of a repository, instead of the entire respository.
Cons
- The traditional model less adequate for distributed teams, remote workers and outsourced teams. This is because you are dependent on access to the server in order to be able to use it. Good internet mitigates this problem.
- It is inflexible. It is difficult to make copies of the repository. Sure you can create as many working copies as you need, but making a complete copy of the repository including the history is difficult. It's also not possible to merge from repository to repository (at least not easily or without additional tools).
- If you use a traditional repository to house multiple projects it will grow and grow as time goes on. Eventually it will become bloated and unwieldy. You may have to archive old projects, so there is a larger maintenance cost associated with administering traditional version control.
The distributed model
The distributed model of version control is a peer-to-peer system instead of the client-server approach of the traditional model. Rather than a centralized server, each node in the distributed network is a full repository. Users make changes in their working copy and then commit those changes to their local repository. Changes can then be exchanged (pushed or pulled) with other repositories.
Distributed version control is absolutely fantastic for working with code, however all distributed systems currently have problems with binary assets and very large projects (although Facebook are working on this for Mercurial).
There has been something of a competition between Mercurial and Git. Personally I prefer Mercurial, but I also commonly use Git for open-source work.
Pros
- Very effective for distributed teams, remote workers and outsourced teams.
- Distributed systems are built to work offline and great for when you are travelling. Like working in a cafe? Do it, bank up commits while you are offline, synchronize with your master repo when you are back in the office.
- It is very easy to fork (or clone) a repo. This makes backup and archiving easy. It makes it easy to work with multiple side-by-side copies of your code-base.
- There is much less risk of losing a repo in the event of a disaster such as server melt-down. There will likely be many clones of a repository distributed among team members so it's much more difficult to lose your repository. With a traditional centralized system, if you lose your central repository you lose the history of all your projects.
- Technically no server is necessary, although for convenience you will most-likely designate a particular repository on a particular PC as the master repo.
- Makes for a very flexible workflow. You can easily emulate the traditional structure with a master repo and multiple client repos, however you aren't limited to this layout.
- The main distributed systems are open source and free.
- No need to check out before editing, it figures it out for you (actually SVN does this as well, although annoyingly Perforce doesn't).
- Very easy to ignore files (to be fair SVN also allows this, however in both Git and Mercurial the ignore setup is stored in a simple version controlled text file).
Cons
- The model is difficult for people to understand and it is hard to explain. Even some coders have trouble understanding the concept, try explaining it to someone less technical!
- The support for binary files is woeful! They are not great at dealing with binary assets, especially large binary assets. I've noticed there are large file extensions but I haven't tried these.
- Not so great at dealing with large projects (I'm talking about gigabyte project sizes).
- Performance tends to degrade as project size increases.
- You might end up with many repositories, especially if you churn through projects quickly (as we do at Real Serious Games). This can become difficult to manage. It can be tricky to remember which projects contains what. This can be handled somewhat with good process and documentation.
- Distributed version control doesn't allow partial syncing. You can't sync just part of a project, you must sync the whole project. This makes a lot of sense when you understand the nature of the distributed system, but if you come from the traditional model you might miss the ability to sync only a portion of a very large repository. This is a good reason to keep your distributed repos small and lightweight.
Version control and game development
Games have unique problems to solve that normal software development projects don't have to deal with. As a game developer you have some different requirements from your version control toolset.
Disciplines and teams
To start... people other than coders also work on games. By necessity game teams combine individuals from the disciplines that are required to construct a game. Coders often have little trouble using version control (after some experience). However the other disciplines (artists, designers, producers, QA, etc) can find these tools complicated and overwhelming, especially when it comes to merging (something many coders even find difficult).
Good training, education and a commitment to continuous improvement can help the wider team be successful with version control. If you are a coder you can help by creating scripts and tools that make version control easier to use for the other team members, although small studios with precious little resource may struggle to achieve this. At a minimum coders should always be available to help team members through version control issues.
Game teams come in many sizes and structures. The smallest teams have 1 or 2 people. The largest teams can have 100s of people collaborating. Version control systems generally scale well to large teams. There are many huge software development companies with 1000s of coders using version control. Large teams are at least a solved problem for version control.
Binary assets
Normal software development projects mostly version control code (eg text files). Games usually have a mix of both text and binary assets. There's code, configuration files and various other text assets. Then there are binary assets such as meshes, textures and levels/scenes.
Most version control systems were designed to handle source code and really struggle with the massive binary assets that are common in game development. In particular the distributed version control system really struggle with binary assets and large projects. Things are changing though, for instance Facebook are now using and improving Mercurial for their huge code-base.
A key feature of version control is the ability to merge source code that has been simultaneously edited by multiple programmers. Unfortunately this doesn't work at all for binary assets! These are not mergeable through version control, this creates a horrible process bottleneck where only one person can work on a binary asset at a time. To have multiple people working on a binary assets causes situations where one person (if not more) must lose the work they have done.
Some version control systems allow assets to be locked and this is an acceptable, if not great, answer to this problem. This ensures that only a single person can edit a binary asset at a time and no one is at risk of losing their work. Of course this is only possible in traditional systems, the very nature of the distributed systems prevents locking. Now you could make a plugin or some other method to roll your own locking system, but that's busy work that takes you away from actually making games.
If you are unable to lock binary files due to your choice of version control system you must find another way of dealing with this issue.
Process and workflow
One thing you should definitely do is strive to modularize your work to make it easier to distribute tasks among the team without causing conflicts. Coders do this already when we make code modules. We split the code up file by file. One developer can then work on one file, another developer can work on a different file, and there will be no merges needed so long as the developers are working on separate files. The more separate modules we create the more likely it is that developers can work without interfering with each other and the risk of merge conflicts is minimized. To some extent this approach can also be taken with assets... Meshes, textures and scenes can all be divided up into modules (and loaded/streamed at runtime) meaning there is less chance that artists and designers will overlap in the assets they need to edit.
Another way to deal with this problem is to have a process or work-flow. Many people use a system I like to call who has the asset? In this system one person at a time can claim ownership of the asset. In that time only that single person is allowed to edit the asset. This system is enforced only when the team follows the rules defined in the process, by this I mean that the team must be disciplined enough to stick to the rules. Each team member must understand what assets the others are currently working with and must respectfully restrain themselves from working on assets that are currently claimed by others. If you are all in the same room this isn't particularly difficult, just call it out to the team as you work! Or maybe write it up on a whiteboard to keep track of who has what. For those in distributed teams you can achieve this via online communication, something like Slack will do the trick.
You might justifiably be thinking what a horrible process or how did the games industry get to this point. Yes this is crazy-far from an ideal situation. Unfortunately sometimes we we are reduced to tactics like this because of our situation, team or choice of technology and we still need to get the job done with some shreds of sanity remaining!
Release management
Another interesting problem for game developers is that we often go through projects more quickly than normal software development. Software projects often last for many years. Games on the other hand can be over quickly, the smallest games are created in a matter of months. The trend of mobile games combined with improved technology means that games are being built more quickly than ever before. This begs the question what do we do when the project has finished? We need to retire the project and archive it, although it would be good if we could access the project again later for reference or to pull out code and assets for a different project. As we'll soon see some version control systems handle this sort of thing better than others.
Games, like traditional software projects, often need to manage and maintain multiple releases. At some point you will need development and production versions of the code. Often, games also have multiple versions being developed in parallel. For example it's not uncommon to have released an alpha build that you are taking feedback on, updating and re-releasing. At the same time other team members are separately working towards the beta version. Then there's that one person who had to fork the alpha release and hackup a prototype demo to show at PAX.
You see what I mean. We need multiple versions of a project with multiple people contributing to each version. Each separate version of the project can't interfere with each other. Don't take a breath yet, there's more. You also eventually need to consolidate the changes from all projects into a single master version. For example you'll have fixed some bugs in the alpha version that you need to bring forward into the beta version. If you are new to development this might sound like a complete nightmare. Well it can be. But these situations that I am describing are only made possible with version control. It may still seem chaotic and hard to keep track of what is happening and who is doing what, but with version control you have a means to manage and control the chaos and guide it in a sensible direction. The tools you have at your disposal are branching, forking and tagging. Distributed version control systems excel at managing multiple versions.
Version control and Unity
Unity has integrations for Perforce and Plastic SCM. These can make your life easier if you are working with either Perforce or Plastic. Unfortunately there is no built-in integration for Subversion, Mercurial or Git. The code for these plugins is open-source and you can find it on Bitbucket. If you look in the code you can see there is support for SVN! However SVN hasn't yet been included with Unity. If you search on the asset store you will find various packages that support Mercurial and Git, although I don't really think it's necessary, personally I think Mercurial and Git work pretty well with Unity without needing a plugin.
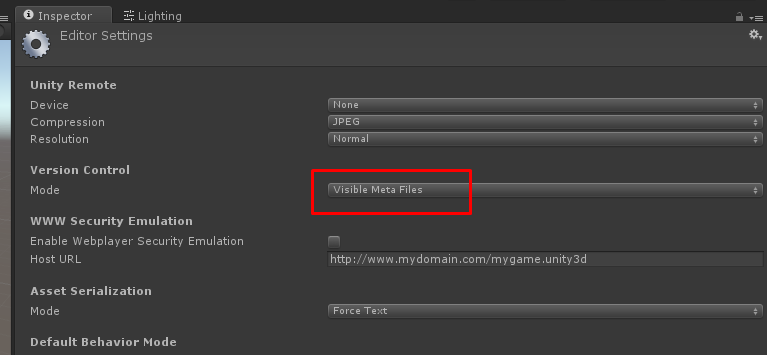
If you aren't using Unity's version control plugins then you should set Version Control Mode to Visible Meta Files as mentioned in the Unity manual.
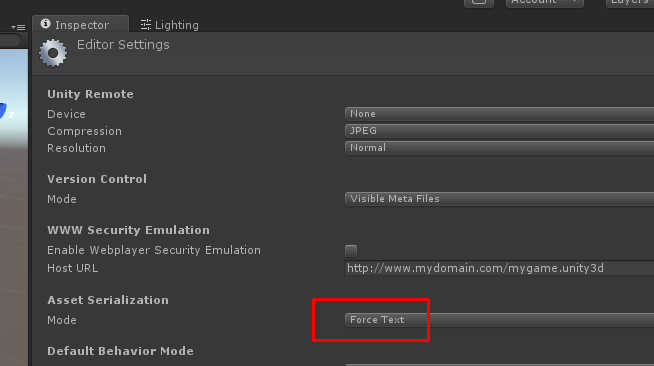
Where possible I also like setting Asset Serialization Mode to Force Text. This causes assets like project settings, meta files and scenes to be stored as text files. This is arguable, but the benefit of this is being able to view differences when committing assets like scenes that normally are stored as binary and are hence not diffable. This can help you understand the structure of Unity assets. Unfortunately this setting doesn't scale very well to very large projects and can cause problems with 3rd party packages from the Asset Store. In these cases you should set it to Mixed for large projects. Force Text is most useful for small projects, especially when you are learning about Unity data formats.
Issues
Editing scenes and other binary assets
Editing Unity scenes and other binary assets is a massive process bottleneck. Normally only a single artist or designer can work on these files at the same time.
Using Force Text (mentioned earlier) can help. This will store your scene files as text files so it becomes possible to merge them, although merging is rarely easy and Force Text may not be feasible for large projects. If your version control system supports file locking then this will help enforce single user editing of Unity scenes and binary assets.
Even otherwise sophisticated developers can be bought to their knees by this issue. The fact is that only a single team member can work on a scene at one time. I believe this is the single biggest problem that Unity should be fixing.
Modularization can help. Break up large scenes and use streaming to merge them at runtime. Unity 5.3's new SceneManager can help with this.
Don't alt-tab while syncing
When you are syncing a Unity project from version control be careful you don't alt-tab to switch back to Unity. If you do this while the sync is in progress bad things can happen. Imagine this situation: the sync is in progress, your assets and scenes have been updated, although it hasn't yet updated your meta files. You alt-tab back to Unity. Unity then thinks you have a bunch of assets without meta files. So it generates meta files. Meanwhile the version control sync continues and proceeds getting the meta files, however it doesn't get the meta files because it's conservative and doesn't want to overwrite the meta files that were just generated by Unity. Now you open your scene and discover that links to scripts and prefabs are broken!
This isn't just a contrived case, I have seen it happen on multiple occasions. The problem grows larger with repository size, the longer it takes to sync a repository the more chance you have of triggering this behavior.
Techniques for managing releases
Branches, tags and forks are three different techniques to manage your releases. Which you choose depends on your needs and what you are comfortable working with.
Branches
A branch can be thought of as an internal clone of a repository.
When you are working on a repo you will choose which branch to work with. If you haven't created any branches then you are automatically working with the default branch. At any time you can create a new branch based on an existing branch, then you change between branches depending on what you need to work on at any given time.
Developers branch their code for all sorts of reasons. Commonly a branch is created for a particular release, and this allows you to maintain a development version of the repository that is separate to your production code.
I've also known teams to branch for features (they implement a feature in a separate branch before testing it and then merging it back to the trunk). You can also branch by task, team and individual.
Jeff Atwood has a good overview of branching and branching strategies.
Tags
Tags allow you to label a particular revision. This can be a great way of associating a revision with a particular releases or milestone. For example once you finish the PAX Demo you could label the revision with that name. Do this and you have a way to identify code releases in your revision history.
Tags are simpler to work with than branches but they aren't as powerful. For example if you wanted to go back and edit PAX Demo and re-release that code you will find that achieving this with tags is tricky and will likely cause a mess in your revision history.
Forks
Forking or cloning your repository is an alternative to branching.
Where a branch is an internal copy of a repository, a fork is an external copy: a completely separate repository. A forked repository is related to the original repository and code changes can easily be merged between them. Anything you can do with branching you can also do by forking. You can fork separate repositories for development and production, you can fork separate repositories for features, tasks and individuals.
Forking can be more flexible than branching. Once you have branched your repository it remains in your repository and contributes to its size (bloating the repository). Forks of a repository exist externally and this makes it easier to safely dispose of them when they are no longer needed. If you find yourself creating short-lived or many branches you might want to consider using forks instead.
Forks can be easier to understand than branching. After all a fork is simply another copy of the repository. You can see it in your file system. You can't see a branch in your file system, branches only exist through the tools provided by your version control system.
Which to use?
I advocate a balanced approach.
Long lived and highly coupled relationships between repositories should be represented as branches. Development and production branches are a good example.
Short-lived relationships between repositories should be forks. For example your PAX Demo will be over in a matter of weeks. You may need to hack your code to bits, so you'd like to branch. I think forking is a better option here because you will want to retire the repository in a month or so. It's much easier to retire a fork than a branch as a fork can easily be deleted from the file system (or archived to some other folder).
When you have many relationships between repositories you should also consider forking. For example at Real Serious Games we fork code releases at regular intervals (every 3-6 months) from our development repository. We number the code releases starting with release 1. We are now up to release 22. We like to keep these old code releases because we can archive old code and easily revive it should a client come back to us and ask for new features. For us having 22 branches bloating our master repository would not be feasible.
Using version control effectively
Presented here is a my grab-bag of techniques and best practices. These will help you be more effective at using version control.
Just remember, one person's best practice is another's worst practice. Take this advice with a grain of salt. I have tried all these tactics and found them to work well in most circumstances. Rules and process need to be flexible though. The software development business is complex and we need flexibility. Follow best practices when you can, throw them out when then you can't or otherwise adapt them as you see fit.
Training
Make sure everyone is educated on how to use version control. If there is someone on your team who understands it better than you do, have them teach you. If you understand it better than your teammate, teach them. Education and training help solve many of the problems that people have with version control.
Version control everything... except anything that can be installed or generated
Version control any original work that you can't afford to lose. Source code, configuration files, test scripts, source assets.
Don't commit files that can be generated by a setup or build process!
You should have a project setup script that installs 3rd party packages and dependencies. You also need a build script that takes care of everything to create a build from source code and assets. Having these two things makes it much easier for new developers to get started with a project. It also means that installed and generated files don't have to be included in your version control. Including those sort of files in version control bloats out your repository and makes it slow to copy and synchronize.
Code review
Where our process interacts with version control provides us with some natural points at which to conduct code review.
Prior to committing you should conduct self-review or peer-review. Self-review is similar to peer-review, only you are reviewing your own code, however you should pretend you are reviewing someone else's code! That makes it easier to spot the errors in your code.
Those using branches can perform code review prior to accepting code into a branch. For example as you merge code into your release candidate branch you can review it. Or as you merge code into your production branch you can do final code checks before the code gets into the hands of the public.
If you are using distributed version control you have another opportunity to review... when you push to the master repository. This is another chance to ensure that you aren't pushing bad code to your team mates.
Github has a great system that enables remote code review. When you are ready to integrate your changes back to the master repository you submit a pull-request. Someone else should review the pull-request and merge it into the master. If any issues come up during the review the reviewer can annotate the pull-request with queries and issues that should be addressed.
Test before you commit, don't break the build!
Make sure you have tested your code thoroughly before you commit to version control.
Testing and code-review helps prevent issues getting into the master repository. This is the cheapest time at which to find and fix defects. As code and features go further along the pipeline and into the hands of our players, defects become progressively more difficult and expensive to find and fix.
Be careful when you synchronize
Be aware that at any time the build could be broken!
Code reviews, automated tests, continuous integration and conscientious developers can all help minimize the occurrence of broken builds, but human error does happen and sometimes problems can slip through!
When you synchronize with the work of others be ready to stop normal work and fix problems. There will be times when you are become blocked because the build is broken. When this happens, just jump in and get it fixed. Save the retrospective for later, after the build is fixed.
Mistakes happen. Be aware that when you synchronize you are potentially merging problems into your local repository. Do this at a time that best suits you! Then be prepared to deal with any problems that arise so you can get on with your job.
Commit messages
Your commit messages are a form of communication. You are sending a message to your team mates or even to your future self! Be nice to your colleagues. Be nice to your future self. Make sure that your commit messages are meaningful.
As with code comments, the most important thing for commit messages is explaining the intent of the code change. Explain the why rather than the how. In the same way that your code comments shouldn't just explain what you can easily see from reading the code, your commit comments shouldn't just explain what you can easily read by examining the changeset. More important than explaining how the code works... and so many coders seem to fail at this... is to explain the thinking behind the change. Explain why the change was needed and what value it it adds.
Does the change fix a bug? Explain the bug and explain how the change fixes the bug.
At some point, maybe when you are trying to figure when a particular bug was added, you will have to go back and look at an old code revision. When that happens you will be very happy that you wrote meaningful commit messages.
You should also relate commit messages to your process and systems. If you are completing a task from your task tracking system, be sure to include the task number in your commit message. Same for bugs. When you fix a bug include the bug number in your commit message.
It's your diary
I like to think of version control as my diary.
Forgot what you did last week? Forgot what you were doing yesterday? Have a look at your version control history.
When I write commit messages I write them like they are journal entries, ready for someone else to read. Tell a complete story with your commit messages. If you can imagine how someone else will read that story, you will write a better story.
Make small frequent commits
Make small commits, make them frequently.
Small commits are easier to test because there is less to test. They are easier to code review and issues will be spotted more quickly. Many small and well-tested code changes adds up to vastly more stable code. This massively reduces the risk that unknown issues will build up and take you by surprise later. Once you have a humming workflow making frequent small and reliable commits your work will quickly add up to big things. And it will all be working at the end! It's the worst thing discovering nasty issues right before you need to do an important build.
Large commits can hide many issues. What's worse is that those issues can be tangled up together which serves to amplify the problems. Small commits, by their nature, will have few lurking issues and those issues will be easier to detect. There will be less issues and because of this they won't be tangled up together, this again makes them easier to spot and unwind.
Each commit should do one thing, it should be a logical unit and all code changes should be related. Have you heard of the single responsibility principle? We should aim for something similar when committing code. All changes that are a part of a commit should be highly related to each other.
You should definitely separate your commits for behavior changes, refactors and performance optimization. When problems are combined (because you combined them in a large commit) the problems they cause will be more difficult to deal with.
If you are fixing a bug. Make sure the fix is one commit on it's own.
If you are adding a feature, just commit that feature. Don't try and sneak in unnecessary refactoring and formatting changes. Many features will actually require multiple commits, usually though it is not difficult to decompose a large feature into multiple logical units.
If you have trouble making small commits it may be because you aren't planning your work effectively. Complex changes should be planned out and executed in a series of small but related commits. This can be difficult if you are still new to development and you may not have even been aware of the need for it. Work on improving your planning skills, practice deconstructing your work into smaller commits, you'll improve with practice. Small concise commits are a mark of skill and experience.
As with all such guidelines, don't take this too far! Don't break up a large commit just because you want it to look like you are making small commits! Don't make small commits happen artificially just to fit the process. I've seen less experienced coders with massive commits ready to go... then divide it up into small commits so that they satisfy the process. This is just hiding a big commit as a bunch of small commits and doesn't really solve anything. Invariably some of the small commits end up being difficult to explain on their own or just broken. Look for these warning alarms when doing code reviews.
If you need to do a large commit, then just do it. Sometimes we have to make large commits, although generally we should prefer not to. When you must do this, set aside some time for reflection. Ask yourself was there another way that the big change could have been a series of smaller commits? Self reflection is very important for us to grow and become more experienced.
Push frequently
This an extension to make small frequent commits for those that use distributed version control.
Push frequently to your master repository. Push every day where possible. The longer you wait to integrate your work with the team the more difficult merging will become and the more likely it will be that you will break the build.
Long periods without pushing your code increases the risk that your computer will crash and you will lose work. This doesn't happen often, but it can and does happen. It will happen to you at some time in your programming career. How much work will you lose? Push your code frequently and you minimize the work lost if this ever happens to you. If you need some motivation... think of missing an important deadline because you lost your work. Think of what your team mates or boss will think if this happens. Pushing daily (or possibly using an automated backup system) is the only protection you have.
If you are working on an experimental or uncertain feature and you don't want to risk pushing to the master repository, simply fork the master repo and push to that. Of course you have to be using a distributed system to do this.
Keep a clean copy of your repo
It's often worthwhile maintaining two copies of your code on your development workstation. You have one copy for development. You can use the other copy for testing or comparing your changes to the baseline. You can do this with both traditional and distributed version control. With traditional code you just get a new copy of the server repository to a different working directory, although in my experience this is easier with SVN than it is with Perforce. If you are using distributed version control then it is even easier. Just make a separate clone of the master repository.
Having multiple copies of a repository is easier and more effective with distributed version control. Here's an example. Make your changes in your development copy. Test, review and commit your changes. Now push your changes to your clean copy (which will no longer be clean of course). Now test your changes in your clean repo. Do your tests still pass? Code often breaks when you push it to the master repo. Maybe you forgot to import or commit a file? Pushing to a separate clean repo and testing there prevents these kinds of issues being forced on your team mates. Once you have rectified any issues in your clean repo you are now safe to push the changes to your master repo.
Having a clean copy is good when you have a bug in your development repo. You can have two repos side-by-side for comparison. This can help you better understand the changes you have made. It's great for understanding if a bug was just created now or if it was already there. When you have a clean copy you can test questions like this. Run your tests again in the clean copy and you will quickly find out if you have introduced a bug just now or if it was pre-existing in the code.
Revert changes when you need to
Have some experimental code changes that haven't panned out? You've been working on code and you've hit a problem. You continue to brute force your way through the problem. If you commit this problematic code you may spend weeks mopping up the issues. You may have already experienced a situation like this. Refactoring, especially without the safety net of automated tests, can result in horribly broken code that manifests bugs for months afterward.
Coding is often about finding the right path forward. Some paths are clearly better than others and there are some directions that are just plain wrong. If you are heading in the wrong direction you can't just continue pushing forward and code your way out of it. When you recognize a problem with your current direction, stop digging a deeper hole for yourself!
Don't be afraid to revert changes when they aren't going well! If there are obvious problems or something doesn't feel right, simply revert your code, take some time to think, then come at the problem from a different angle. You are already doing small commits... so the amount of work you will lose will be small.
Another alternative is to stash or shelve your changes until you figure out how to solve the problem. Also when you plan to refactor or make experimental changes consider forking or branching so that you can keep your potentially broken changes from affecting your team mates.
Testing
Version control can help with testing. Consider having a separate repository just for recording the results of your output testing (check it out in the Techniques section of the Testing article). When you run your tests you can use your version control system to diff the changes to understand if behavior has changed or something has broken.
Code freezes
There will be times in your development lifecycle when you will want to freeze the code-base.
For example, say you've just released a version of your game to production or maybe you've passed a significant milestone. You need to preserve a version of the game at this point. Inevitably you will have to update and release that build again. At the same time your developers must be able to move forward with work in progress for a future release. You need to keep these streams of work separate so that your developers (who are working as hard and fast as they can) don't break the previously working production build.
If your version control system supports this, use it to enforce the code freeze. Particular version control systems, especially traditional systems, may support configurable read/write permissions. If that's the case remove write permissions during a code freeze. With distributed version control a simple technique is to rename your frozen repo. Rename the repo to something obvious like Frozen Milestone 2. This prevents your developers from accidentally pushing to the frozen code-base.
Of course you also need a work in progress copy of the code-base for developers to continue their work. Distributed version control makes this trivial. You simply fork or clone the frozen repository and continue the work in progress with the new repo.
Branch or fork only when you need to
Remember that each branch or fork that you create requires space in your head to remember what is going on. Keep things simple. Only branch or fork when you have a justifiable reason for doing so or when you have system that makes it easy to understand the purpose of each branch or fork.
If you must have many branches or forks, document the purpose of each so that you don't struggle to remember.
Error recovery and bug investigation
Have you ever accidentally released a significant bug to production code? Has your boss hovered while you desperately try to debug the problem?
Version control can help here, it provides a convenient way out for new problems that have been exposed to your users. Simply rollback or backout to remove the updated and broken code. Revert your users back to a working version as quickly as possible. Then, only when things are back to normal, take the time out to assess what went wrong and investigate the problem.
Is your current revision horribly broken and you have no idea why? Identify the revision that caused the issue you will find the issue is much easier to fix. Often the most difficult part of fixing a bug is finding the code that causes it. I'm sure you've had the experience where it takes days to find the source of an issue and then only 5 minutes to fix the single line of code that was responsible. If you can locate the revision where an issue was introduced it will be significantly easier for you to understand the problem. Understanding the problem is usually much more difficult than fixing the problem.
To find the cause of a bug we must locate it in the code. If you search the entire code-base it's like trying to find a needle in a haystack. Anything you can do to narrow down the search space will help. Often this means using your understanding of the code and some intuition to target particular code modules that you suspect are related to the issue. But also consider this, if you narrow down the search space to a single revision, then your search will be extremely well targeted. The code you must search to find the bug is vastly reduced, especially when you do small commits. This automatically puts you closer to finding the bug. In many cases the cause of the bug will be immediately obvious when you inspect the offending code revision.
The raises the question: how do we find the revision that introduced the bug? The technique you are looking for is called bisection. This is like a binary search applied to your code-base. You have a sequence of code revisions, the latest revision is broken, some past revision is ok: You must search for the revision in-between where the bug was introduced. Of course you can do this manually with any version control system, although this can take significant time and patience, sometimes however even the manual approach is worthwhile, because for the most horrible bugs it still may be the fastest route to the cause of the problem.
Fortunately modern distributed version control systems provide built-in tools for bisection. You'll find it quite amazing once you understand what this means. Bisect tools can significantly speed up your manual process. They also offer the potential for an automated bisection. To build that you will need to have invested in an automated build and test process, that's not cheap but it has many other advantages. In this case the advantage is that we can run a fully automated bisection process. Let it do it's job and when you come back to your workstation it will tell you the revision when the code was broken. To me this feels very much like having superpowers. If you can achieve this your team mates will bow to your god-like coding powers.
Blame
Blame is occasionally useful when you need to identify the programmer that last modified a line of code. Normally I promote shared responsibility of code and a culture without blame. Regardless, sometimes you need to know who was responsible for a particular line of code. This is most helpful in larger companies with many developers, say in a situation where you need to understand a code module you haven't edited before. Blame will let you know who last edited the code you are looking at. Now you can find them to ask what is going on with their code.
Hooks
Version control hooks can be very useful. Use them to detect when someone has pushed to a repository. For example you might want to send a notification when someone has pushed changes to the master repo. Or trigger an automated build and test. More advanced: trigger a server restart when you push to repo on a cloud VM. This is a useful technique for simple server deployments.
Delete old code
Don't be afraid to delete old code. Better to delete it rather than comment it out and have it vying for brainspace when you are reading through code. If you need that code again (most times you won't) you can easily recover it from the version control history.
Don't leave commented-out code in place when it should be deleted. I guarantee that in the future someone (probably your future-self) will have to figure out what to do with that code. Do them/yourself a favor and just delete it now at a time when you best understand that code.
If you do have a justifiable reason for leaving in commented-out code... document that code with comments and state the reason why you must leave the code in place.
Merging
Don't be afraid of merging. If you work with other programmers you will at some point have to merge your code. Sometimes merges go bad and it can be very difficult to resolve them. It's worthwhile learning how to be confident at merging. Create an example repository and practice, practice, practice. Make sure you try a few different types of merge software, not all were created equal and you may find some easier to understand than others.
Don't ever attempt to merge binary files.
Don't ever attempt to merge generated text files. You can simply regenerate such files, so there is no need to waste your precious brain resources trying to merge them (note: generated files probably shouldn't be in version control anyway).
Keep your code clean and well organized. Well-separated code modules mean that coders are more likely to be working on separate modules, so there is less chance their work will overlap and therefore less chance of needing to merge.
Integrate with other tools
Integrate version control with other tools where possible. Visual Studio 2015 has built in Git integration which is very useful. There are Visual Studio extensions for various other version control systems.
If you use Perforce or PlasticSCM and Unity, make sure you look up Unity version control integration.
Where possibly integrate your version control with your continuous integration and continuous delivery systems.
Version Control Software
This section is a stock-take of the version control software that I have used and my thoughts on each.
Please seek Wikipedia for a full comparison of version control software.
Subversion (SVN)
A widely used open-source/free traditional version control system. If you want to use the traditional model and you don't want to pay for a proprietary solution, this is the option you want to use.
It's quite mature and reasonably easy to get started with. I've used this at several companies and it can handle massive repository and many branches.
It's support for binary or large assets is ok.
SVN has a file locking system which can help when you want to prevent multiple people working on the same file at the same time, however this isn't really built into the process as you don't have to check out a file before editing it. In many ways this is good because you can modify files and SVN will figure out for you want have you have changed, but it's bad for file locking because it makes it the user's responsibility to check if a file is locked before changing it. This makes room for user error and means multiple users can edit a binary file, even when it is locked, when the users comes to submit they will find that they must lose their changes if someone else already has the file locked.
Alienbrain
It has been more than 10 years since I used Alienbrain. I found it to be a very robust solution with great support for large binary files and large projects. Alienbrain is built for the entertainment industry and is mostly used by digital artists. It has great integration and support for art tools like 3ds max and Photoshop. It also has good API and is very customizable. Unfortunately it is very expensive which puts it out of range for all except the largest studios.
Perforce
I've used Perforce at various companies. It is something of a standard in the professional industry. It is robust and fairly reliable. It can support massive teams and thousands of branches. It has great performance and it deals well with binary assets and large projects. Unity has built-in support for working with Perforce.
However, there are a some serious downsides to Perforce. Occasionally we encounter unusual bad behavior that isn't reproducible. Our build server sometimes churns out bad builds. It's usually easy to fix by doing a Force get of the assets and a rebuild. We can't be sure if Perforce or Unity is the real culprit here, but this means that I can't say for sure that Perforce is 100% rock solid.
We often seem to battle against random Perforce issues, its arcane API, or its awkward and outdated interfaces. Yes version control can be complicated, it can be tough to understand, however Perforce sometimes seems to go out of its way to make things worse for us. I sometyimes wonder why Perforce is used as much as it is. Of course there are many valid reasons to use Perforce, but personally I have found it difficult to recommend, especially to small studios. It does solve some problems very well, though so whether it's worth considering really depends on your situation.
Due to the rising popularity of the distributed model, Perforce have moved to to take part in the revolution. I haven't tried using this new aspect of Perforce so I can't comment on it, I mention it just because it is interesting to note that Perforce have taken notice of the distributed movement.
One thing that really annoys me about Perforce is that you have to check out a file before editing it. When using Subversion and the distributed systems you simply start editing your code or assets and the software figures out for you what has changed. This is one thing that makes Perforce seem incredibly old-fashioned. Of course the check out before edit model actually works best for binary assets (because it allows these files to be locked - a useful feature of Perforce), but for every other reason it's an unnecessary frustration.
One thing that's great about Perforce and I've mentioned this already, is just how fast it is. Trying syncing a 1 GB project from the repository to your workstation. Perforce will chomp it's way through this faster that it would take to copy a 1 GB file over the same network using your operating system. You end up wondering did it really get all the files?
I have no idea how Perforce can copy files so quickly, it seems like magic. The flip side of this equation is that Perforce is incredibly stupid. I've already mentioned that Perforce can't figure out what you have changed, you have to check out before editing. Of course you can use the Reconcile offline changes feature, but that's painfully slow on a large project. There's also the caching system that makes Perforce very fast to copy files. That's great for performance, but it means Perforce doesn't keep up to date with what's actually currently in your working directory. For example you can delete part of your working directory then do a Get latest and nothing will come down. As far as Perforce is concerned you are still completely up to date! That's because Perforce isn't checking your working directory for it's state, it's checking its cache and it's cache is out of date.
Like I said Perforce is not smart. Also Perforce doesn't adequately clean up deleted files from the working copy. This is a painful problem when some deleted DLL gets left in a project and causes a build to fail. Due to Unity's bad error messages relating to DLL problems you might not even be able to find out which DLL is causing the problem! The standard way to do deal with this is by deleting the project and doing a force get in Perforce. (Force get must be used to override Perforce's cache which prevents Perforce from understanding that you have deleted part of your working copy, again stupid Perforce.) Now the force get will complete reasonably quickly, Perforce is fast at that sort of thing, but now you have to reimport the entire project into Unity which could take an hour or more (for a large project). This is all because Perforce doesn't properly clean up its working directory when files have been deleted.
So to summarise. Perforce solves some problems very well. It's fast, it deals well with binary files and large projects. It allows files to be locked which stops multiple people from editing binary files.
However there it also causes plenty of problems. Perforce is old, their tools are complicated, slow and buggy. You'll have to workaround various issues with your workflow and the maintenance cost for keeping it working chews through time and resource. Answers on how to solve problems with Perforce can be hard to come by and although it's easy to get started with it is extremely difficult and time-consuming to master.
Perforce offers a massive amount of control and flexibility, this is good but to make use of it you'll have to deal with their commands and APIs which can be inconsistent and difficult to work with. The outputs of Perforce commands can be tricky to parse.
If you must work with Perforce please check our open-source NodeJS API. We believe this is a simpler abstraction over the Perforce API. If it doesn't do exactly what you want, please contribute on Github.
Mercurial (HG)
Distributed version control is a fantastic way to manage code. This applies whether you are a solo developer or a team. When I first started using distributed version control I loved that I could bank up commits whilst commuting to work on the train. Then when I arrived home in the evening I could push all my work to the master repository on my NAS box. Distributed version control has also worked well for the development team at Real Serious Games, I talk more about that soon.
I like Mercurial because it's simple, at least I believe it is simpler than Git. It's very reliable and it's easy to setup and use.
If you are looking to get started with Mercurial there is a great tutorial online by Joel Spolsky. The official tutorial is also good.
If you get into Mercurial, make sure you check out The Definitive Guide.
BitBucket is a great online hosting solution for Mercurial and integrates well with Atlassian's other tools.
Git
Git is another distributed version control and is the main alternative to Mercurial. Git is the most popular DVCS, especially in the open source space. Git and DVCS generally have been catapulted into our consciousness driven by the rise and rise of GitHub.
I use Git (both personally and at Real Serious Games) through my open source development on GitHub. In most respects it's very similar to Mercurial. GitHub generally makes it very easy to administer a Git repo. Git though is actually quite complex and flexible. This can be useful if you want to build an extremely customized development workflow, although I prefer Mercurial because I prefer a VCS to just work without requiring any setup or customization. Like I said though if you use GitHub that makes Git quite simple to use and in fact if you are using something like SourceTree then you rarely have to even care whether you are working in Mercurial or Git.
Here's something to help get you started with Git.
Git also has a great reference manual.
GitHub is a great hosting platform and is free for public (open-source) repositories. Bitbucket can also be used to host Git repositories, unlike GitHub though Bitbucket offers free private repositories.
SourceTree
I thought it was worth mentioning SourceTree. This is a tool from Atlassian that can be used as a UI for both Mercurial and Git. It smooths over the (few real) differences between these packages, to the point that you rarely have to care which type of repository you are actually using.
Unfortunately, as of this writing, the most recent versions of SourceTree have been a massive bug-fest. Personally I have stuck with version 1.6.25 until things improve, you can easily install this version via Chocolatey.
Software to watch
These are some software packages that I'm very interested in. If anyone has experience with these and has a story to tell please contact me.
Plastic SCM
Plastic SCM is a relative new comer to the VCS scene and I am following it with much interest. They are targeting the games and entertainment industries. Plastic SCM aims to be some intersection of traditional and distributed models.
Unity has built-in support for Plastic SCM, this is a massive endorsement for this package, but is it deserved?
Alternatives to version control
This article wouldn't be complete with mentioning alternatives to version control for collaborative work.
Dropbox
Dropbox is a fantastic way to share work in simple collaborative environments. It's a convenient way to share assets and documents with your team. It's a great way to share builds with your play-testers.
However, there are plenty of potential problems:
- Don't use it as your primary copy of data. If you do that you risk having a team mate accidentally delete your work.
- Dropbox doesn't handle conflicts well and it has no way to merge simultaneous work that has been done on a file.
- Dropbox sucks up internet bandwidth. This is ok on a LAN and you can limit it. This is bad when you are on a mobile data connection.
In addition Dropbox doesn't track versions and so you can't recover old revisions (unless you pay for the very expensive Pro version). If you find yourself wanting to track versions then you should really be using a proper version control system and not Dropbox.
Don't ever ever combine Dropbox with a version control system. In the past I tried putting a Mercurial repository in Dropbox, that ended in a corrupted repository. The problem is the way Dropbox deals with conflicts. This means that if two people attempt to work with repository at the same time there is very high likelihood that the repository will be destroyed by Dropbox's conflict resolution. You have to be very very careful if you want to work this way and there is every chance that it will end in tears. This can happen even if you are a solo developer!
Google Drive
I regularly use Google Drive for personal and collaborative work on documents, spreadsheets, forms and presentations. It's great for that sort of stuff, although I couldn't imaging using it for sharing code or working on a software project. One thing that is very cool is that you can create scripts to automate and customize your Google Drive workflow, that's the only time I work on code that's stored in Google Drive. It comes with a basic IDE/code-editor which makes for a terrible development experience, but I'm not complaining, it's very cool that it is possible to script Google Drive and that this service is free!
Google Drive can also be used in a similar way to Dropbox and that comes with same sorts of problems I've already mentioned.
What we use at Real Serious Games
Our needs at Real Serious Games are quite unique. Our work is fast-paced and demanding. The techniques and technologies that win at RSG are the ones that tend to be the simplest and provide the most benefit for the least headaches. When things get in the way of our ability to deliver a product, one of two things happen: We make it work, somehow or someway, otherwise we get rid of it.
We use Mercurial for our long-term internal code-base and it works pretty well.
We use Git and GitHub for our interaction with the open-source world. Possibly one day we will completely convert to using Git for all our code.
For our Unity projects and art assets we use Perforce. This is because Perforce is easy to explain to our less-technical staff and it is easier for them to understand. It's also because Perforce is generally fast and works well with binary assets and large projects. Perforce allows partial-syncing of projects. Perforce allows us to lock binary files, which stops multiple people working on them simultaneously which prevents merge issues. We have plenty of issues with Perforce that we must deal with, however at this point in time its benefits still outweigh its disadvantages.
We have put some effort into our open-source scripting API for Perforce. If you are using Perforce this might also help you.
Conclusion
In this article I've talked at length about version control. Why it's useful. How it's essential for development, especially in collaborative teams. Also how it relates to game development. I've reviewed the software packages that I have experience with and I have shown what we currently use at Real Serious Games.
Both the traditional and distributed models of version control have strengths and weaknesses. You really need to understand what's important to you and your team before you make a decision. Which ever decision you take you will need to deal with problems, because no matter which version control software you choose, it will cause you some problems.
Of course there are many unresolved issues. Most distributed VCSs have poor support for binary files and large projects. Is this just because they are new and don't yet have the maturity? Maybe. It could also be because the nature of distributed model makes it difficult to solve those problems. I am not sure.
I can only hope that the distributed systems eventually rectify these problems, because distributed systems are amazing and they really are the way of the future. Yet these unresolved problems make life difficult for game developers. Maybe someone reading this article will rise to the challenge and start work on a new open-source distributed system that perfectly fits the needs of game developers? Will it be you?
Resources
Wikpedia: https://en.wikipedia.org/wiki/Version_control
Intro to version control: http://guides.beanstalkapp.com/version-control/intro-to-version-control.html
Visual guide: http://betterexplained.com/articles/a-visual-guide-to-version-control/
Distributed visual guide: http://betterexplained.com/articles/intro-to-distributed-version-control-illustrated/
Git vs Mercurial: https://importantshock.wordpress.com/2008/08/07/git-vs-mercurial/
Mercurial tutorial: http://hginit.com/
Mercurial reference: http://hgbook.red-bean.com/
Git tutorial: http://gitimmersion.com/
Git reference: https://git-scm.com/book/en/v2
Subversion reference: http://svnbook.red-bean.com/en/1.7/svn.basic.version-control-basics.html
Perforce: https://www.perforce.com/our-customers/game-development
AlienBrain: http://www.nxn-software.com/
Plastic SCM: https://www.plasticscm.com/version-control-for-games.html
Comparison: https://en.wikipedia.org/wiki/Comparison_of_version_control_software
Reviewers
Dylan Ford, Honeyvale Games
Dylan is a programmer/designer and soon to release his first game, Alchemy Punch. He's also pretty excited about the game you're working on, so tell him about it!
Jason Stark, Disparity Games
Jason Stark is a 20-year veteran of the games industry and a 23-year veteran of raising children. He has one games studio, four daughters, not much hair and even less time. His studio, Disparity Games, consists of him, his wife and whatever daughters happen to be available at the time. They have spent the last year releasing Ninja Pizza Girl and still aren't done yet.
Daniel Vicarel
Special Thanks
Mark Hanford
For becoming my second sponsor on Patreon.